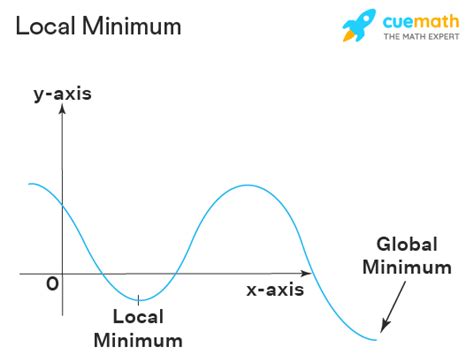
Understanding the intricacies of finding local minimum efficiently in optimization problems is crucial for various fields including machine learning, operations research, and finance. With the exponential growth in data, the challenge of optimizing complex, high-dimensional functions has become ever more pressing. This guide provides expert insights into the methodologies and practical techniques that can streamline this process, ensuring both accuracy and efficiency.
Key Insights
- The importance of gradient-based optimization techniques in finding local minimum efficiently
- The technical consideration of convergence rate in relation to optimization algorithms
- An actionable recommendation to leverage hybrid methods combining gradient descent with heuristic approaches
Finding a local minimum in multi-variable functions requires both strategic planning and precise execution. Gradient-based optimization techniques such as Gradient Descent and its variants, including Stochastic Gradient Descent (SGD) and Mini-batch Gradient Descent, have proven highly effective. These methods, which use the gradient of the objective function to iteratively update the solution, offer a pathway to efficient local minima. Gradient Descent’s appeal lies in its simplicity and broad applicability across various domains, despite its occasional vulnerability to local minima traps.
Analysis of advanced gradient-based techniques, such as Adaptive Gradient Methods (AdaGrad, RMSProp, Adam), offers deeper insights into their efficiency and suitability. For instance, Adam, a popular choice in machine learning, adjusts learning rates based on past gradients, providing adaptive learning rates that facilitate faster convergence. In complex, high-dimensional spaces, these adaptive methods can navigate saddle points and converge faster than traditional gradient descent, thus ensuring a more efficient local minimum finding process.
A technical consideration in gradient-based optimization is the convergence rate, a critical aspect that impacts the overall efficiency of these algorithms. Convergence rate refers to how quickly an algorithm approaches the local minimum. Techniques like momentum and adaptive learning rates are instrumental in enhancing convergence rates, making the optimization process not only faster but also more reliable. In practical scenarios, this means less time spent on iterative updates and more productive engagement in problem-solving or model fine-tuning.
Practical Implementation of Optimization Techniques
The practical application of these techniques involves a meticulous choice of the optimization algorithm based on the specific characteristics of the function to be optimized. For convex functions, traditional gradient descent can be highly effective. However, non-convex functions, common in deep learning applications, often necessitate more sophisticated algorithms such as Adam or RMSProp. Leveraging hybrid methods, which combine the robustness of gradient descent with the adaptiveness of adaptive gradient methods, can be particularly beneficial. These hybrids provide a flexible framework that can pivot between deterministic and stochastic updates, thus navigating the trade-off between exploration and exploitation efficiently.What is the primary difference between gradient descent and adaptive gradient methods?
Gradient descent uses a fixed learning rate for all iterations, whereas adaptive gradient methods like Adam adjust the learning rate based on the historical gradients. This adaptation helps in achieving faster convergence and escaping local minima.
How can one determine which optimization algorithm to use?
The choice of optimization algorithm should consider the nature of the objective function, the dimensionality of the problem, and computational resources. For convex functions, basic gradient descent suffices. For non-convex, high-dimensional problems, adaptive methods like Adam are recommended.
In summary, the efficient finding of local minima in optimization problems is a complex task that benefits significantly from a nuanced understanding of gradient-based methods and their technical nuances. By choosing the right optimization technique and considering the convergence rate, professionals can ensure more effective and faster optimization processes. This expert-driven approach facilitates not only better solutions but also enhances the overall efficiency in tackling optimization challenges across diverse fields.